动机
在 AR 取得成功的同时,仍需考虑 AR 带来的局限:
- AR 的生成用时是
的 - AR 的 left to right 限制了生成的顺序,可能限制了建模能力(例如逆向回答)
- 生成了就 fix 住了,没法走回头路
因此 dllm 的动机是多方面的:
- 并行解码 / 规定解码次数,加速生成
- 给模型更自由的生成顺序选择空间,不对生成顺序做假设,追求更好的生成效果
- 填空一样的可控的生成
- 生成中随时修正
还有一个意外之喜:
- dllm 更会吃数据,数据有限的情况下,dllm 的拟合能力更强
概览
Diffusion LLM 一般分为两种:
连续的 diffusion(真正意义上的扩散)
- 某种程度上跟 Vector Quantised 的过程差不多,受到量化误差的严重影响
离散的 diffusion(将连续空间上的扩散改为离散空间中的状态转移),又有两种路线:
用随机的 token 表示噪声,效果一般
MDLM(mask diffusion language model)用 [MASK] 表示噪声
绝对的主流,唯一经过大规模验证的路线
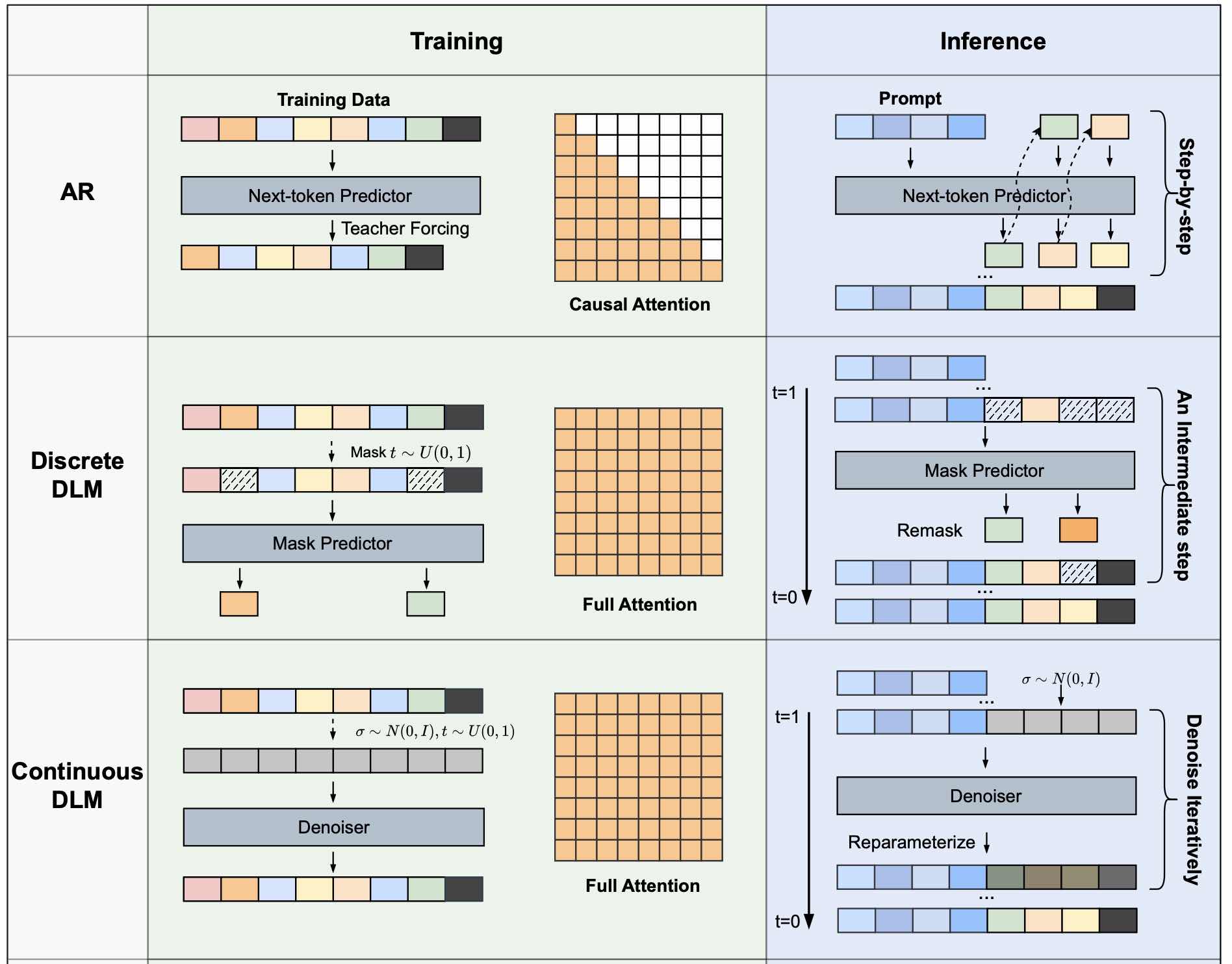
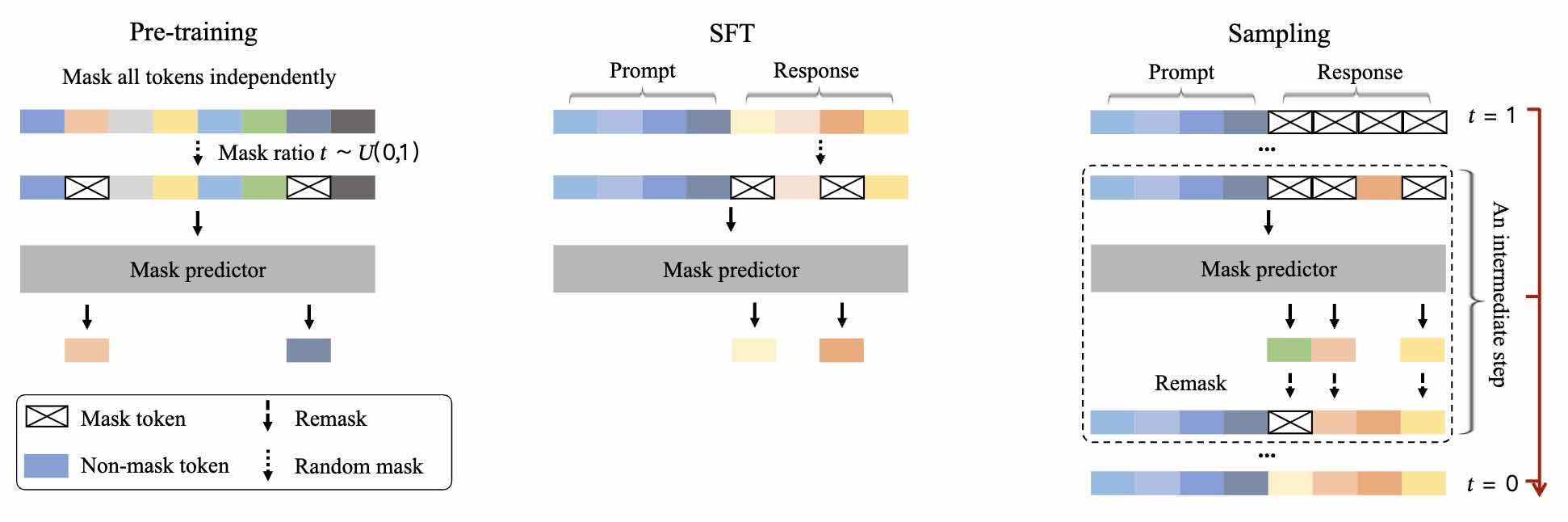
解码阶段,每一个 step 中,进行 unmask 和 remask:
- 如果 unmask 的 token 没被 remask,那么生成成功
- 一般不对之前生成成功的进行 remask
例如生成长度为
常用的 remask 的策略:
- 随机 remask
- 基于 confidence(保留 top-k),常用的 confidence:
- 概率 p
- top-1 p 和 top-2 p 的 margin
- 负熵
- 基于 confidence(保留超过阈值的生成)
最近的进展
旗舰级别模型
- Gemini Diffusion
- Mercury(inception)
- Seed Diffusion
- 盘古 Diffusion(7B)
- RND-1(radical numerics,30BA3B)
- SDAR(上海 AI lab)
学术界常用模型
- LLaDA,人大,蚂蚁(相当于 LLaMA 的地位)
Scalability of LLaDA:
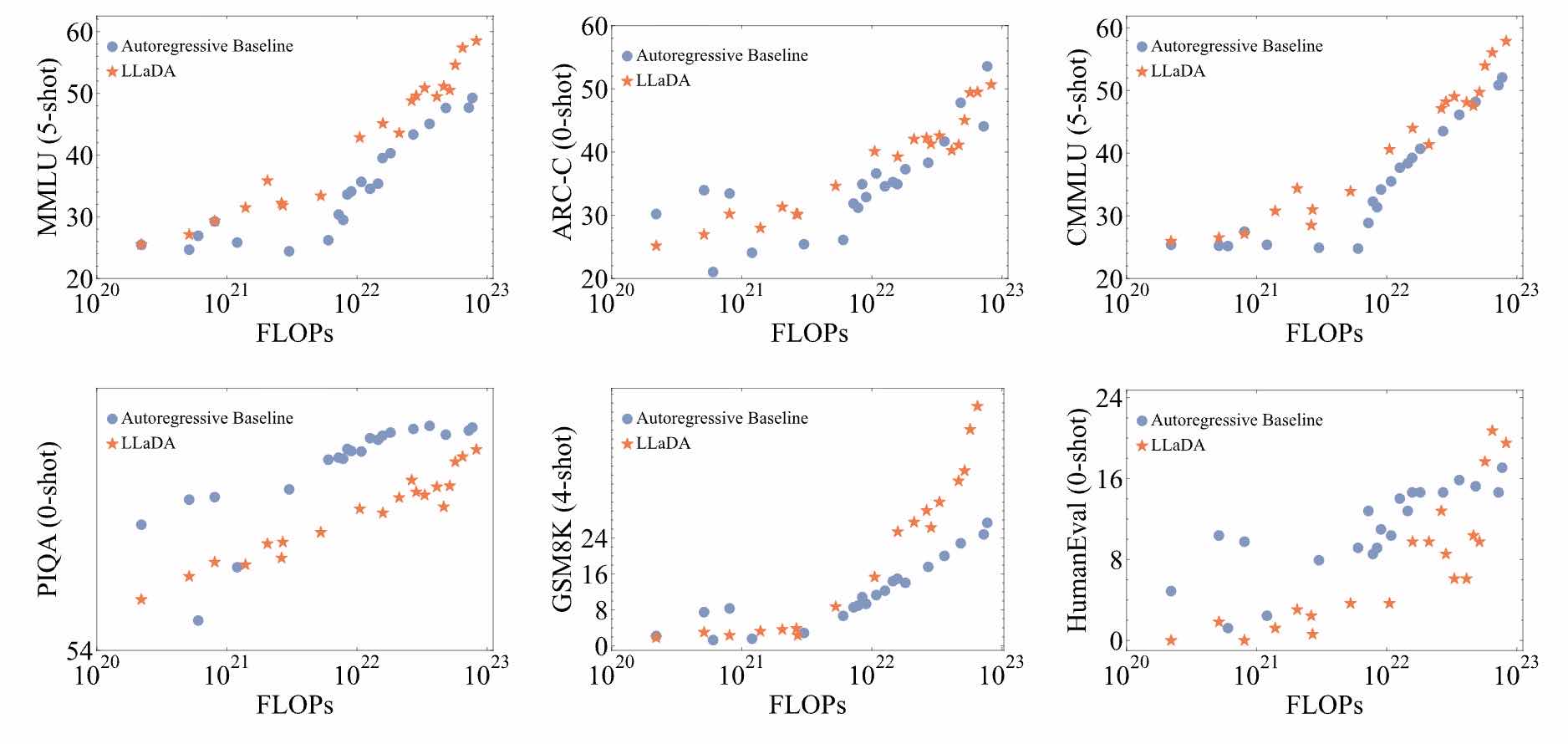
Diffusion Language Models are Super Data Learners 也认为扩散语言模型在数据稀缺时表现优于自回归模型
逆向建模能力:
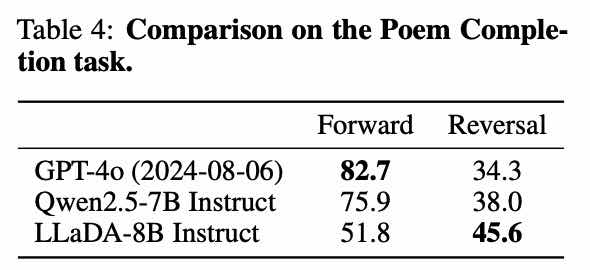
LLaDA 后面还有一系列工作,例如拓展到多模态的 LLaDA-V,更先进的 LLaDA1.5、LLaDA2…
- dream,香港大学(相当于 Qwen 的地位)
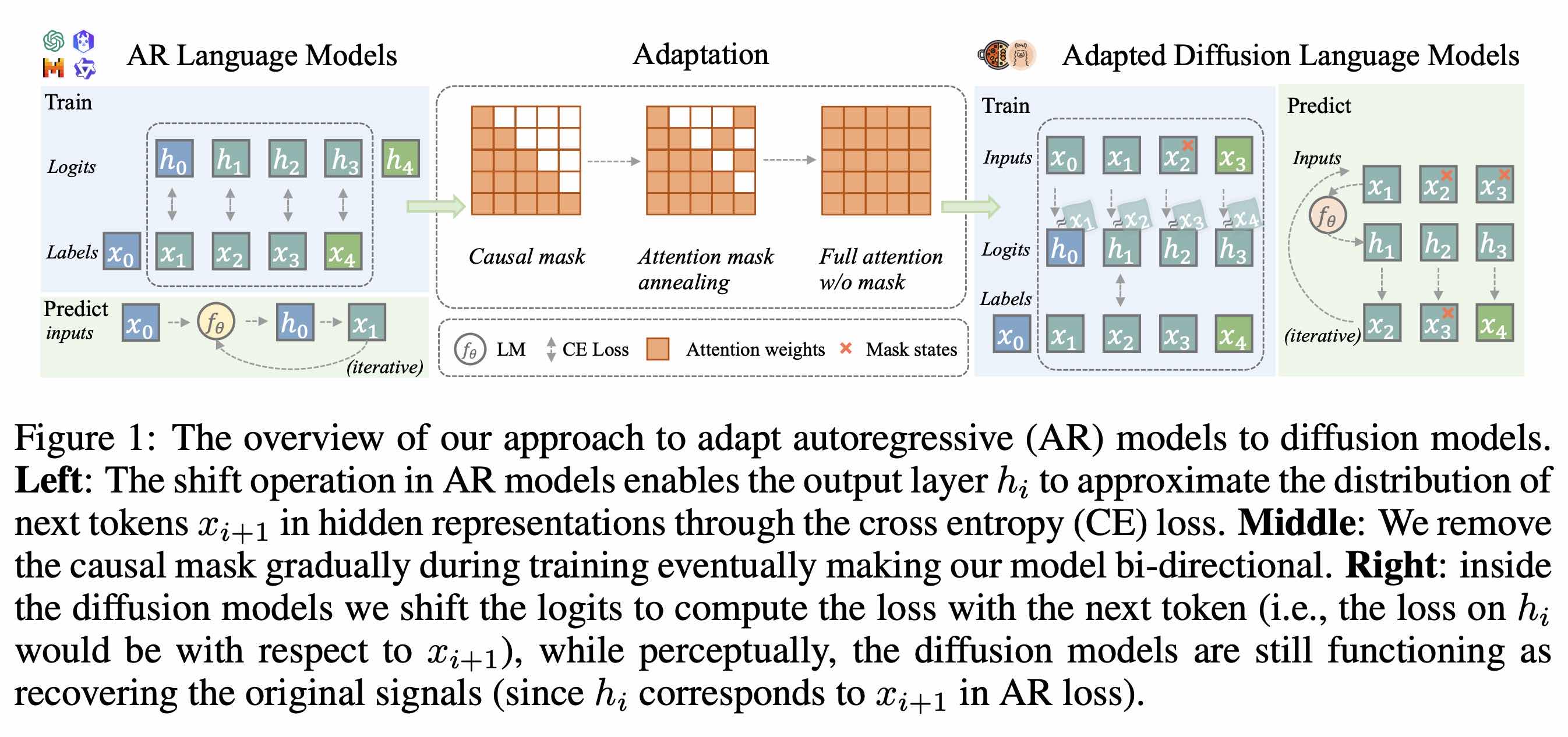
前置工作是 DiffuLLaMA,将现成的 AR 模型转为 MDLM,dream 基于 Qwen 2.5
如果第 i 个 token 是 [MASK],那把第 i-1 个 token forward 的 logits 拿来解码
灵活机制
- Seed Diffusion(字节)
是一个非常复杂的工业级别的工作,此处介绍其有关灵活机制的部分:
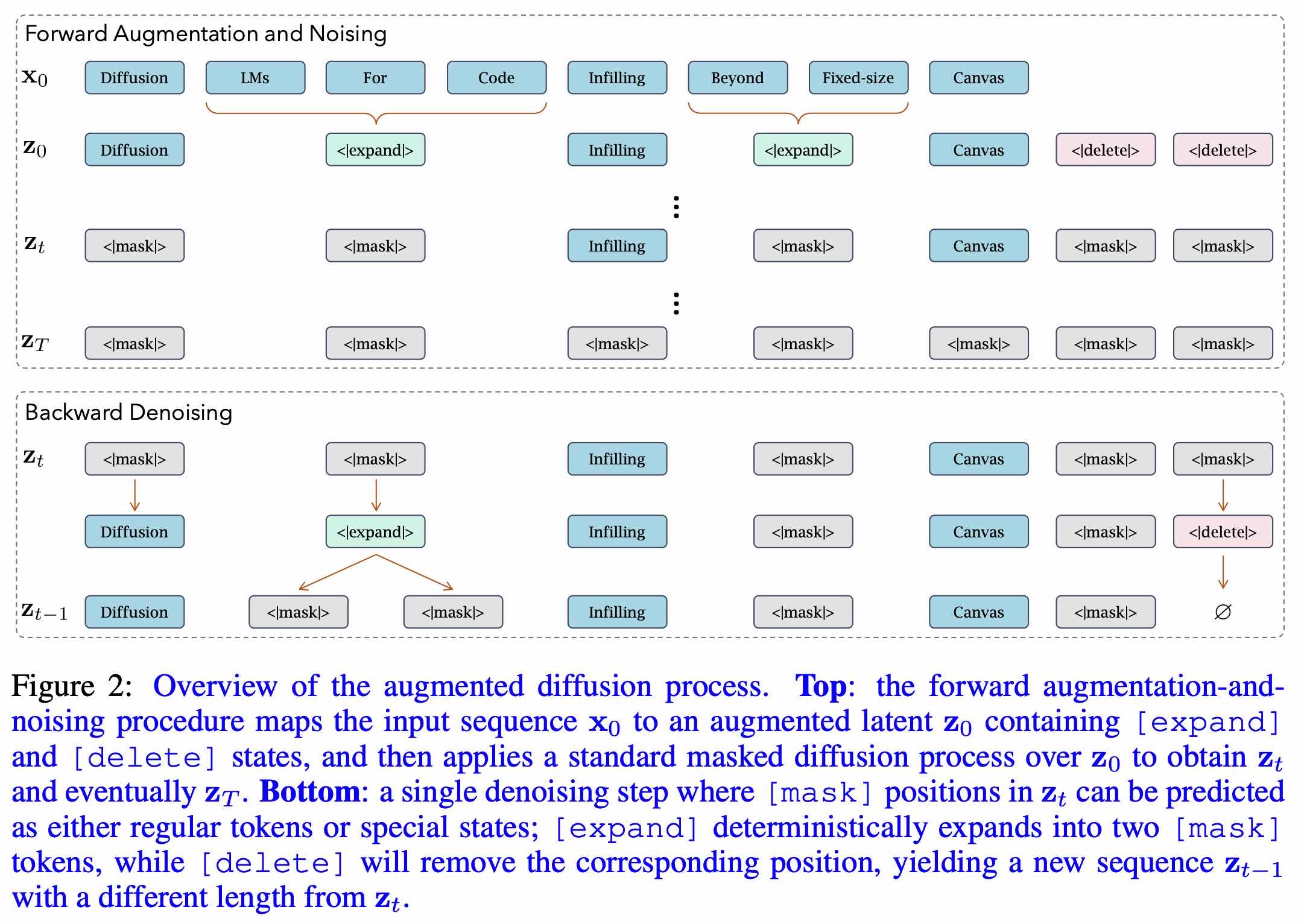
阶段一,基于掩码的扩散训练:此阶段采用标准的掩码填充任务,通过动态噪声调度将部分代码 tokens 替换为 [MASK] 标记。模型在此阶段学习代码的局部上下文和模式(如规律、结构、特征分布等)补全能力。
MASK 阶段训练会带来“伪相关性依赖”(spurious correlations),即模型会相信非 MASK 的 token 为正确的 token,为了缓解这一情况我们引入了阶段二的训练过程。阶段二,基于编辑的扩散训练:为促使模型评估全局代码的合理性,此阶段引入基于编辑距离约束的插入/删除操作来构造噪声。这种扰动强制模型重新审视并修正所有 tokens(包括未被直接操作的部分),从而避免对未污染上下文的“伪相关性依赖”。
第一阶段是课程学习
第二阶段让 [MASK] 和已生成 token 变成平权的,都可能被 remask
- DreamOn(香港大学)
动态生成影响序列长度的 token
混合 dllm(semi-AR)
- Block Diffusion(Cornell Tech,Stanford University,Cohere)

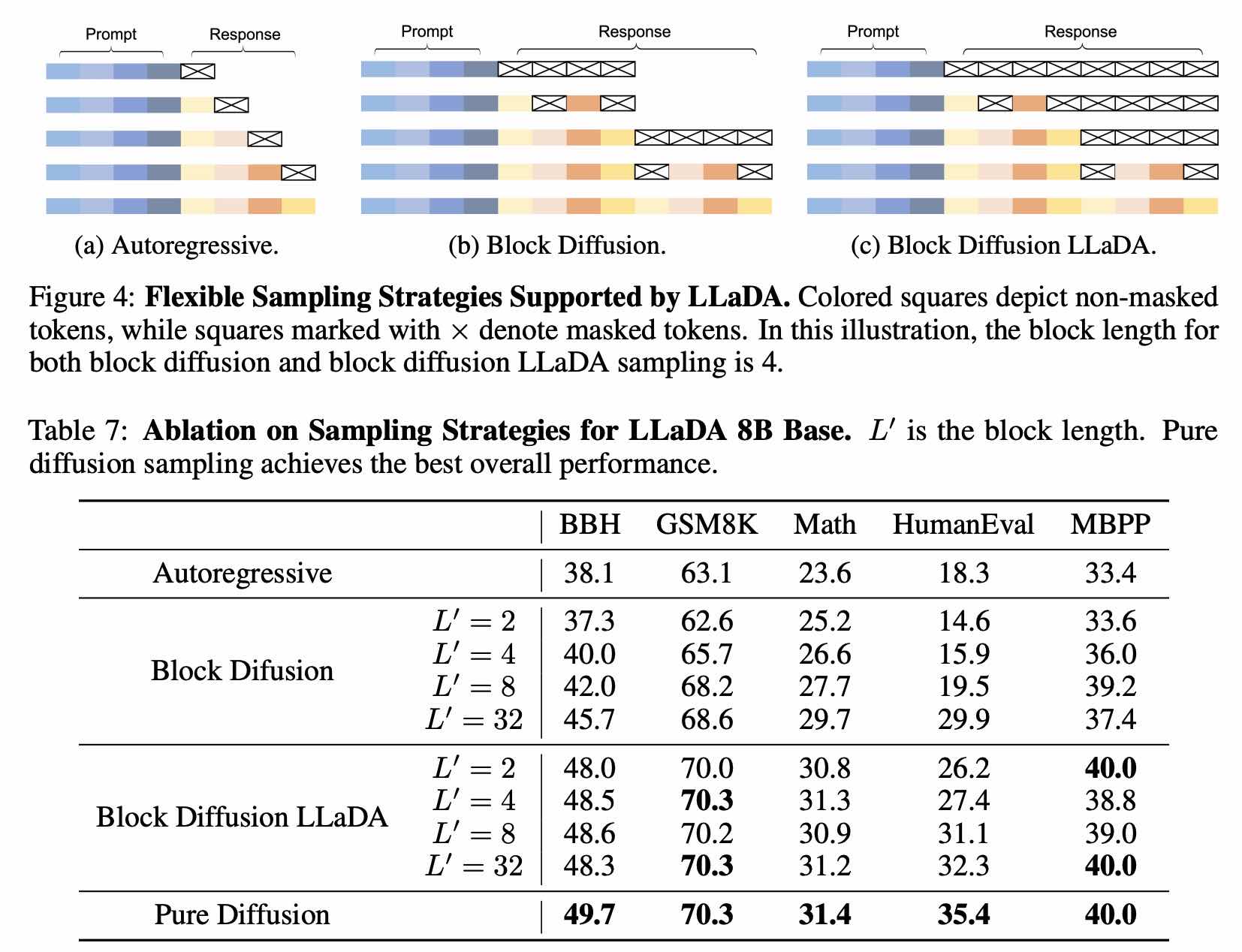
前面提到的 llada 也做了 Block Diffusion 的实验:
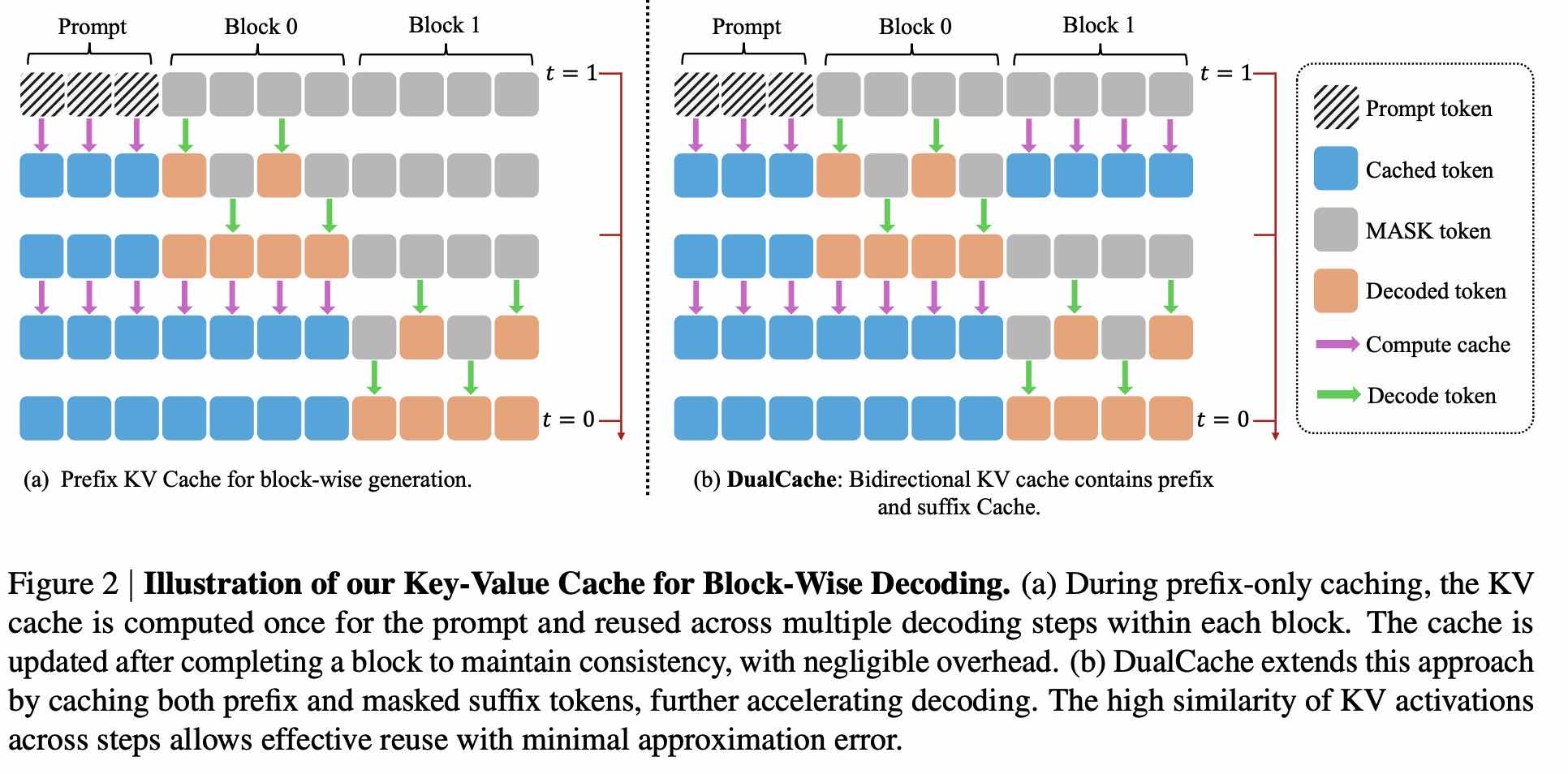
- Fast-dLLM(英伟达)
两个设计:
- 并行解码:每一步不再计算当前步需要解码几个 token(实际上大部分工作里每步解码的 token 数量是个常数),而是只要 confidence 大于一个阈值就解码
- Block Diffusion + KV cache
- TiDAR(英伟达)
背景知识:投机采样(Speculative Decoding)

TiDAR 每次 forward,都是在验证当前 draft,并为当前 draft 的每种可能都生成下一步的 draft
例如 draft 长度为 3,生成 draft 的方式就是 Block Diffusion

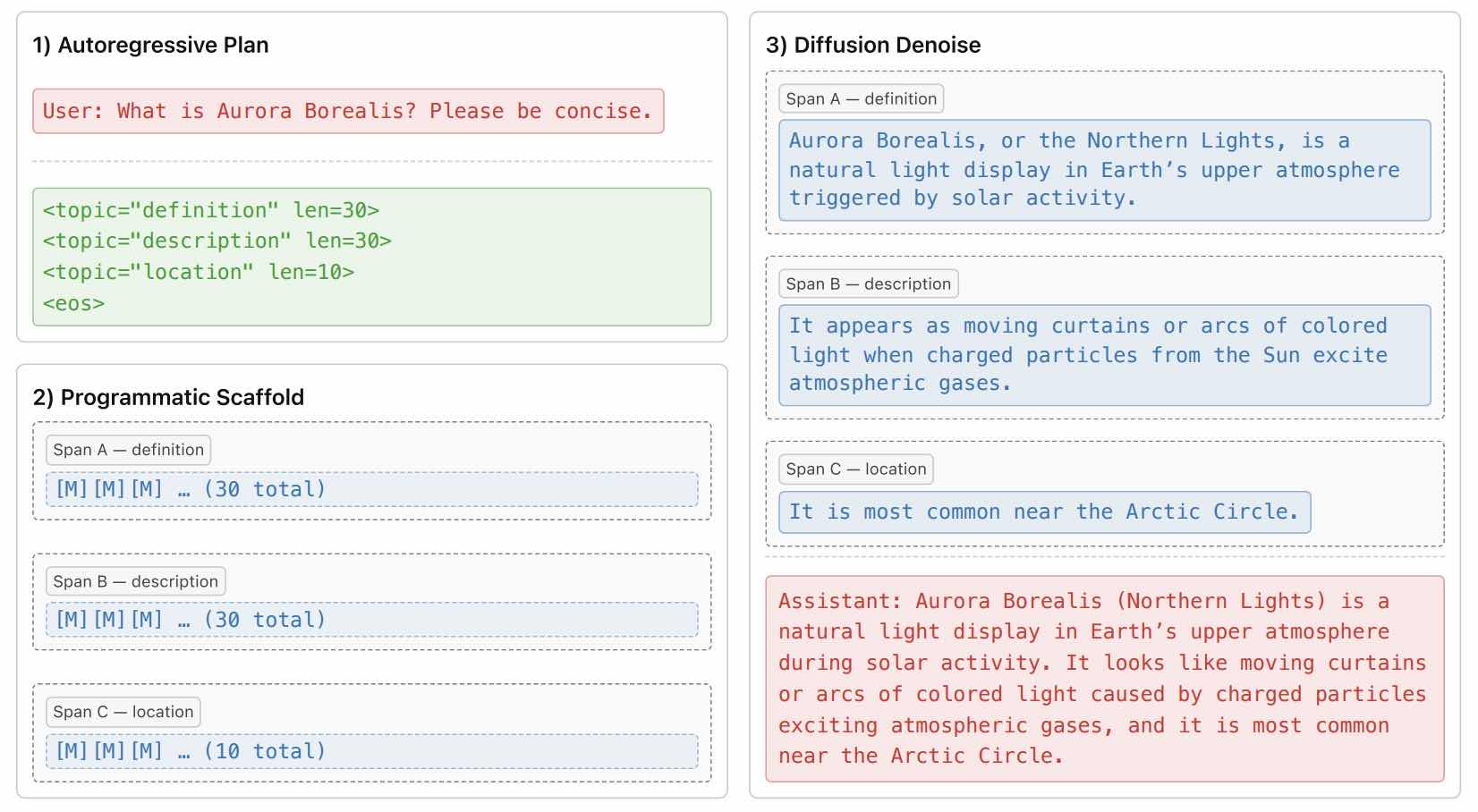
- Planned Diffusion(UCLA)
AR 做规划,dllm 做补全
多模态
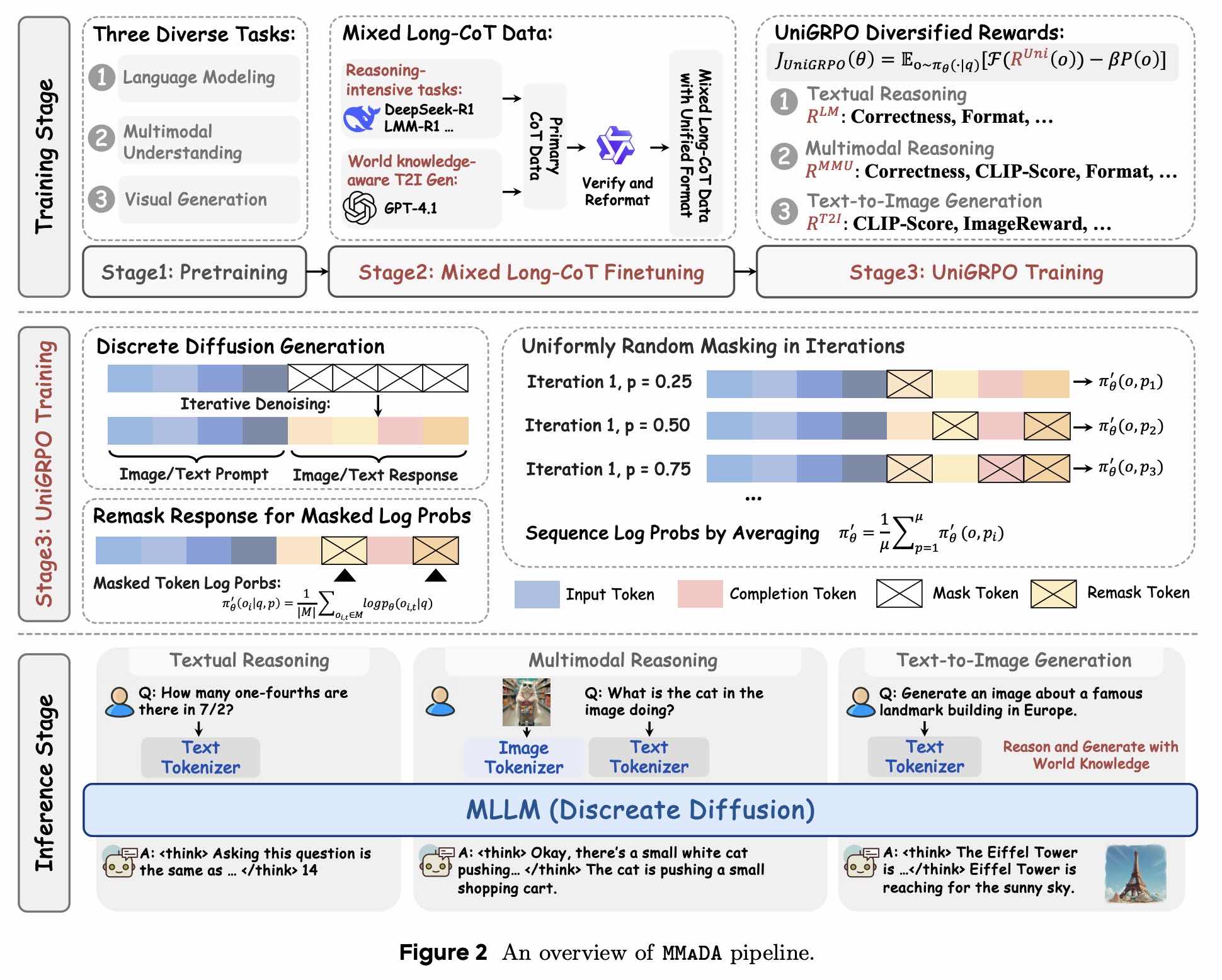
- MMaDA(普林斯顿,字节)
多模态、多任务的统一模型
dllm 的 RL 训练
- d1(UCLA)
Diff-GRPO 首次为 dllm 引入强化学习算法
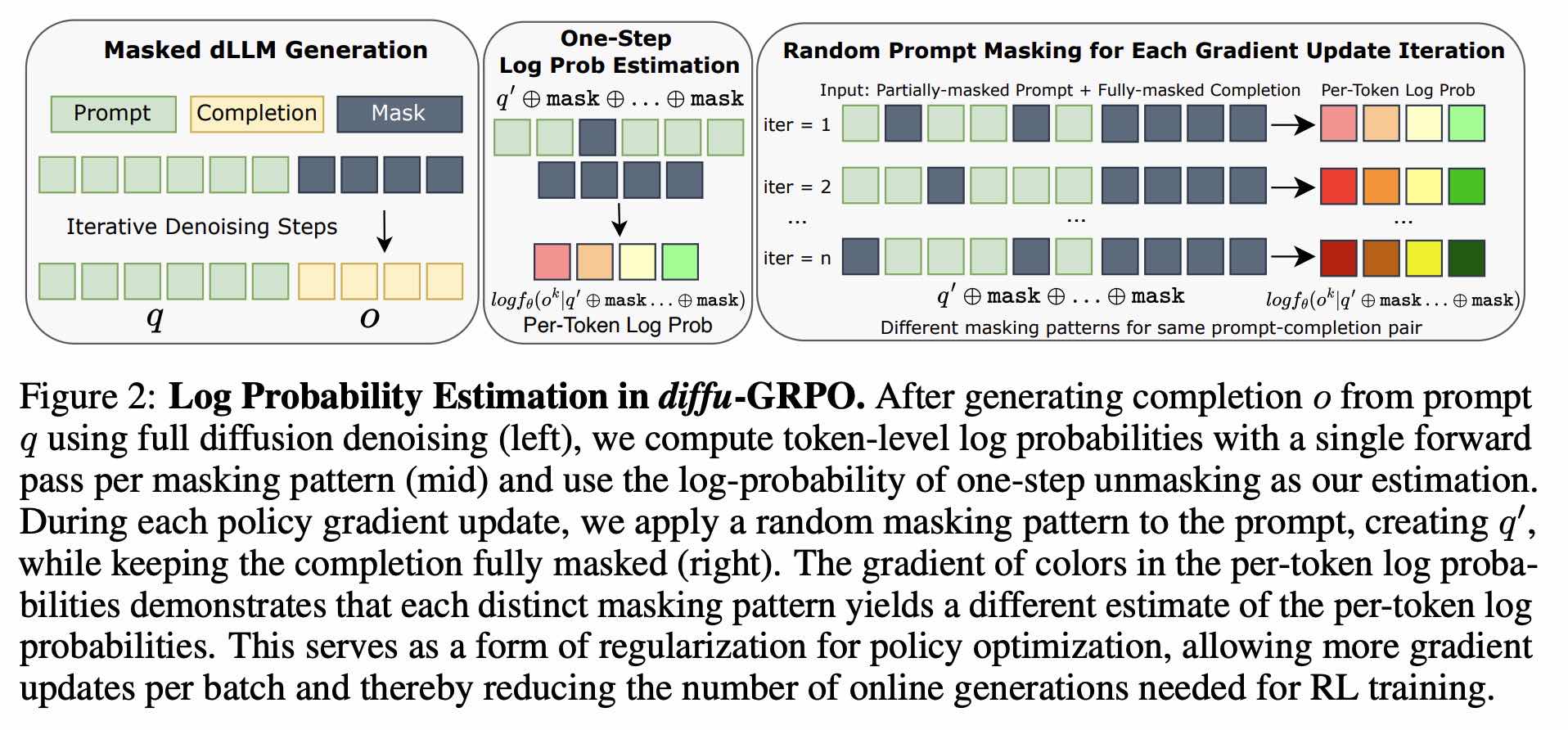
- 对 prompt 做 mask 的意义不明
- 模型实际上只在初始去噪步骤上进行训练
- 上面的 MMaDA
UniGRPO:没必要估计所有 response token 的 log prob,RL 更新过程同样可以模拟扩散过程
- DiffuCoder(苹果)
coupled-GRPO:构造互补的 mask 情形,降低估计的方差
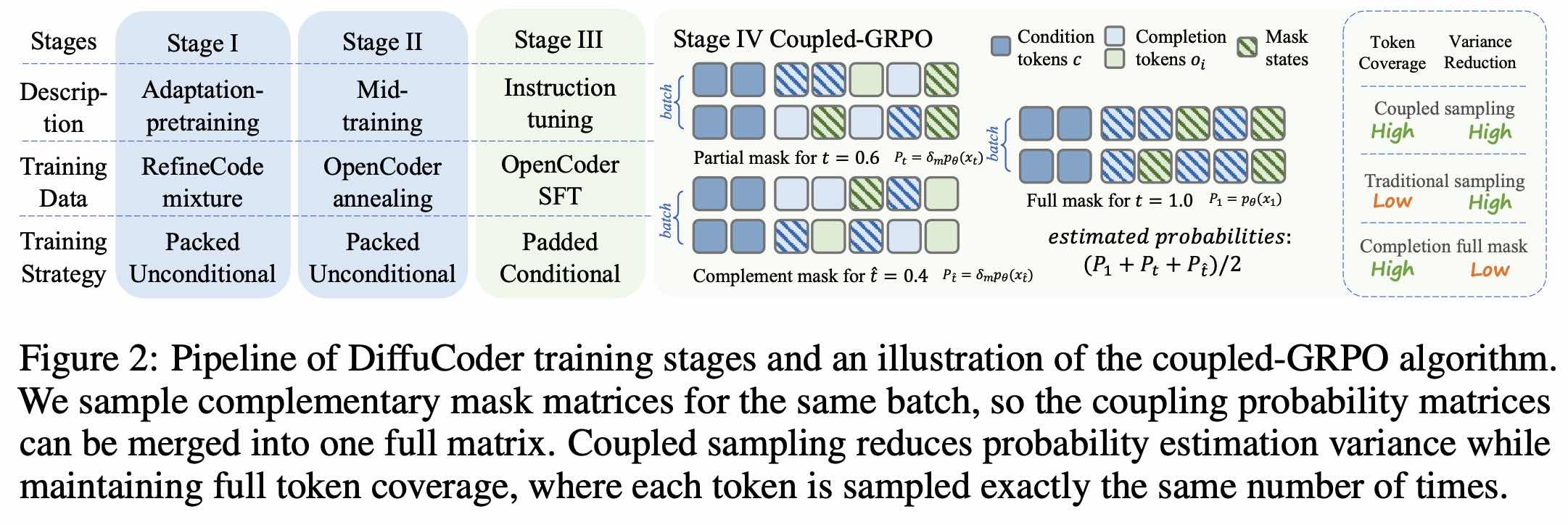
dllm 框架
- https://github.com/inclusionAI/dInfer(蚂蚁)
- https://github.com/ZHZisZZ/dllm(伯克利的学生)
- https://github.com/OpenMOSS/DiRL(OpenMoss)
- https://github.com/Gen-Verse/dLLM-RL(普林斯顿,MMaDA 那一批人)
存在的问题
full attn 导致 dllm 实际上慢于 AR models,最关键的动机实际上并没有做到
基本都退化成 block diffusion
并行解码实际上对性能影响显著
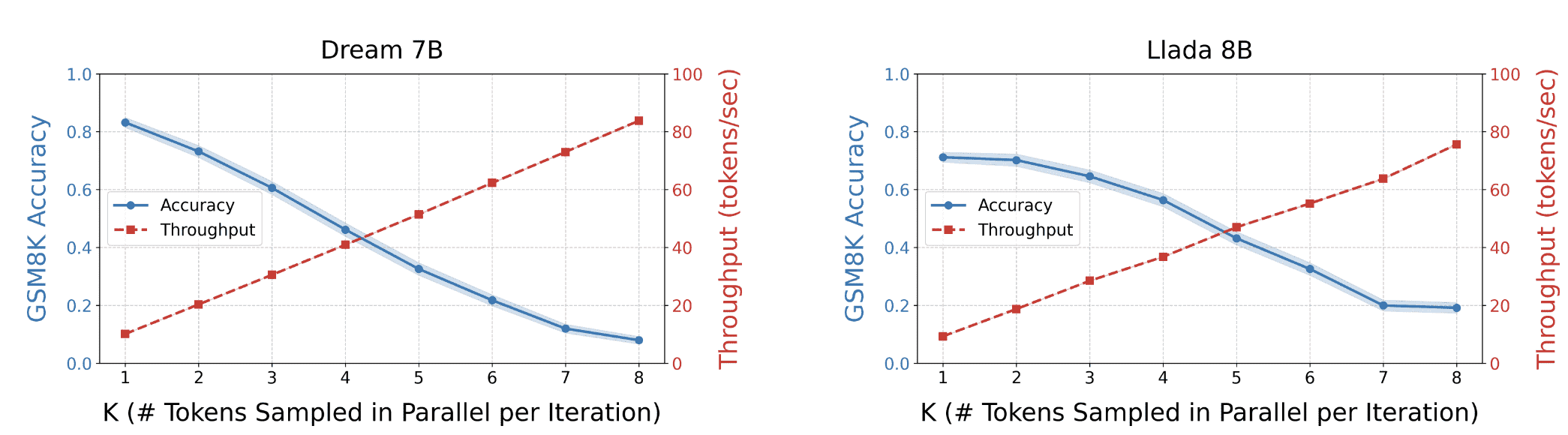
并行解码中独立性带来的冲突
不过 fast dllm 有一个数学证明,如果每次并行解码 p 最大几个 token,冲突的概率不会很大
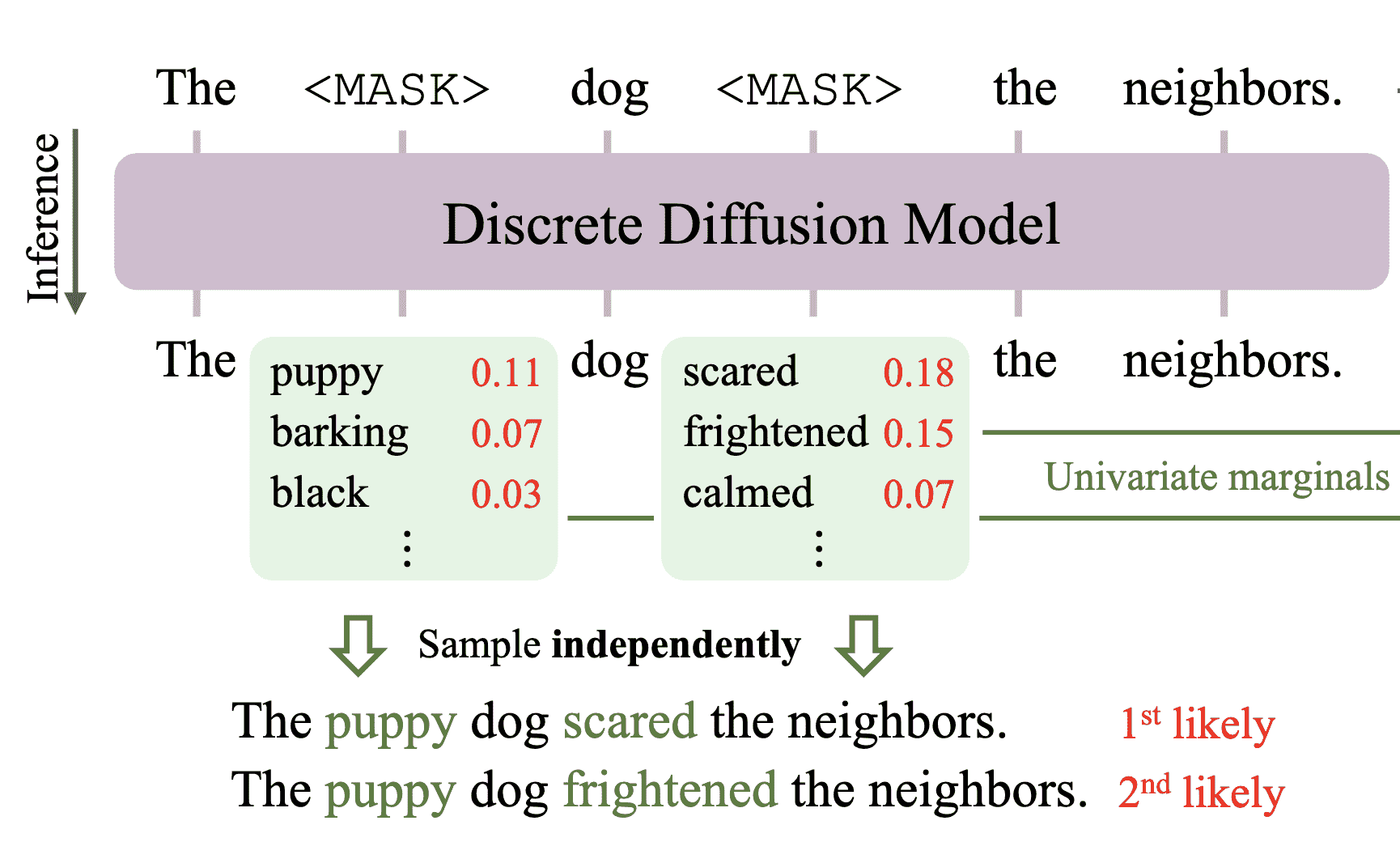
- 从左到右是否已经是 LM 最优的顺序?